|
Computer-Grundlagen
Generell gilt bei den weißen Textstellen auf dieser Seite: Man fügt die Zeichenfolge aus dem weißen Feld bei dem blinkenden Cursor des Terminals ein - dann drückt man die Eingabetaste. Die Sprache eines Computers besteht nur aus zwei Zeichen:1 und 0 Dabei sind 0 und 1 nicht die üblichen bekannten Zahlen, sondern sie sind Abkürzungen für Spannung vorhanden und Spannung nicht vorhanden. Man könnte auch a und z nehmen. Aber die Zahlen 0 und 1 kommen dem menschlichen Verstand entgegen, gerade wenn es um Rechenoperationen geht. Jedes Zeichen der Tastatur muß in diese Sprache (Binärcode) übersetzt werden. Z.B. Für den Buchstaben a lautet der Binärcode 01100001 Werden Zeichen über die Tastatur eingegeben muß dafür Speicherplatz zur Verfügung gestellt werden der natürlich unterschiedlich groß benötigt wird. Ein 8-stelliger Binärterm (so wie der für den Buchstaben a) verbraucht 1 Byte Speicherplatz, sozusagen die kleinste Computer-Speicherplatz-Einheit. Man kann sich im Terminal die 8-stelligen Binärterme anschauen durch |
| printf "%s" 1234567890a | xxd -b | sed -r 's/.{7}$//' | sed -r 's/^.{10}//' | tr -d '\n' | sed -r 's/ *$//' | pr -t |
|
00110001 00110010 00110011 00110100 00110101 00110110 00110111 00111000
00111001 00110000 01100001 Natürlich kann man an Stelle 1234567890a auch beliebige andere Tastaturzeichen schreiben. Man erkennt für die einstelligen Zahlen zu Beginn jedes Blockes 0011. Dies ist vielleicht der Hinweis daß es sich um eine Ziffer handelt. Bei dem Buchstaben a beginnt der Block mit 01. Dies ist vielleicht der Hinweis daß es sich um einen Buchstaben handelt. Der Prozessor kann an einer Stelle eine 1 zu 0 oder eine 0 zu1 ändern, Spannung anlegen oder entfernen. Damit kann z.B. eine Addition von zwei Ganzzahlen durchgeführt werden. 1+2=3 (Man beachte 0 + 1 = 1 und 1 + 1 = 10, die vier Anfangszeichen 0011 werden bei der Addition nicht berücksichtigt) 00110001 + 00110010 = 00110011 Ferner kann der Prozessor diese Binärterme nach vorgegebenen Regeln an andere Speicherplätze verschieben. Damit kann z.B. eine Multiplikation mit 10 durchgeführt werden. 3 x 10 = 30 |

|
Blauer Speicherblock wird durch grünen Speicherblock ersetzt. Mehr kann
der Prozessor nicht machen. Natürlich gelten die Additionsregeln nicht für Buchstaben und daher muß eine Unterscheidung von Buchstaben und Ziffern erfolgen. Jede Programmiersprache muß zuerst dem Computer mitteilen wieviel Speicherplatz und welche Regeln für einen Binärterm zu verwenden sind. In bash braucht man sich nicht darum zu kümmern. Das wird im Hintergrund durch die Programmierung erledigt. Verwendet man aber Elemente einer Programmiersprache in bash muß man sich auch darum kümmern. Ein Beispiel ist printf hier steht z.B. d für eine positive oder negative Ganzzahl (integer) s für Zeichen, Buchstabe oder Zahl oder Sonderzeichen oder Kominationen davon (string) f für eine Kommazahl (float) Die Schreibweise für printf lautet grundsätzlich, z.B. für die Zahl -42 |
| printf "%d\n" -42 |
|
-42 % bedeuted daß im folgenden das Format festgelegt wird. Dann wird die Art des Binärterms notiert, dann wird ein Zeilenumbruch notiert. Die Anführungszeichen besagen daß die Format-Eigenschaften vollständig darin enthalten sind. Anschließend wird nach Leerzeichen eine Zeichenfolge angegeben (die auch in Anführungszeichen geschrieben werden kann) auf die das Format angewendet wird. Stimmt die Zeichenfolge nicht mit der Art des Binärterms überein: |
| printf "%d\n" aB |
| bash: printf: aB: Ungültige Zahl. |
| printf "%f\n" -42 |
|
-42,000000 Die Ausgabe erfolgt als Kommazahl (keine Punktzahl wie sonst in bash) mit standardmäßig 6 Stellen nach dem Komma. Und auch die Eingabe muß als Kommazahl erfolgen, NICHT ALS PUNTKZAHL. |
| printf "%f\n" -42.587 |
|
bash: printf: -42.587: Ungültige Zahl. Die zentrale Fähigkeit des Prozessors ist also die Änderung der Speicherplätze von Binärtermen und das anschließende Zusammenführen verschiedener Speicherplätze. Alles muß dem Prozessor in diesen Sinneinheiten verständlich gemacht werden. Die Übersetzung in Maschinensprache wird von einem Programm übernommen das als erstes die beteiligten Zeichen in die entsprechenden Binärterme übersetzt und zum Schluß alles wieder in verständliche Zeichen übersetzt. Und hier begegnet man dieser Speicherplatz-Verschiebung wieder: |
| echo beispiel | sed 's/p/m/' |
|
beismiel sed gibt dem Prozessor die Anweisung den Binärterm des Buchstaben p zu ersetzen durch den Binärterm des Buchstaben m - durch Änderung der Speicherplätze. |
| echo beispiel | sed 's/...\(.*\)/\1e im end\1/' |
|
spiele im endspiel sed gibt dem Prozessor die Anweisung: nach 3 Zeichen - durch die 3 Punkte beschrieben - bilde einen neuen Speicherplatz - beschrieben durch die zwei Klammern \(\) die maskiert werden - und gib diesem Speicherplatz den Namen \1. In diesem Speicherplatz werden beliebig viele Zeichen hinterlegt - beschrieben durch .* - nämlich alle Zeichen bis zum Zeilenende. Ausgegeben wird dann der Inhalt des Speicherplatzes \1 dann der Binärterm der Buchstaben e im end und schließlich nochmals der Inhalt des Speicherplatzes \1 sed arbeitet in der Regel zeilenweise, aber man kann mit sed auch über mehrere Zeilen arbeiten. Dazu wird eine mehrzeilige Variable erzeugt: |
| sA=$(echo -e "ZeileA\nZeileB\nZeileC") |
| echo "$sA" |
|
ZeileA ZeileB ZeileC Nun ein mehrzeiliges Kommando indem die 1.Zeile nach unten verschoben wird: |
| echo "$sA" | sed -n '1h; 1!p; ${g;p}; ${g;p}' |
|
ZeileB ZeileC ZeileA ZeileA sed wird mit -n aufgerufen um eine automatische Ausgabe zu verhindern. Dann wird in ' ' explizit angegeben was gemacht wird. 1h bedeuted daß die erste Zeile auf einen besonderen Speicherplatz kopiert wird den man holdspace nennt. 1!p bedeuted daß der Speicherplatz aller Zeilen erhalten bleibt mit Ausnahme der ersten Zeile ${g;p} bedeuted daß der holdspace an den Speicherplatz der bisherigen Zeilen angehängt wird. p ist der Befehl daß der entsprechende Speicherbereich in verständliche Zeichen zurückzuübersetzen ist. Ein weiteres Beispiel: |
| echo "$sA" | sed -n '1{s/Z/T/g;h};2{s/l/g/g;p};3{s/ei/ah/g;p};${g;p};${g;s/A/22/g;p}' |
|
ZeigeB ZahleC TeileA Teile22 1{s/Z/T/g;h} bedeuted daß im Speicherbereich der ersten Zeile der Binärterm des Buchstaben Z in den Binärterm des Buchstaben T geändert wird. Dann wird dies auf den Speicherplatz holdspace kopiert. Es gibt keine Anweisung daß die erste Zeile zurückzuübersetzen ist. Der Speicherbereich der 1.Zeile wird durch s/Z/T/g wirklich geändert. Es ist nicht so daß die Änderung durchgeführt wird und in den holdspace kopiert wird und die erste Zeile so bleibt wie sie war. Dieses Verhalten ist bei der sed-Ausgabe im Terminal zu erwarten. Aber bei den Befehlen an den Prozessor ist dies anders. Man kann das überprüfen indem man die 1.Zeile zuerst in den holdspace kopiert, dann die erste Zeile ändert. Im nächsten Schritt wird die erste Zeile zurückübersetzt und dann wird der holdspace angehängt und zurückübersetzt: |
| echo "$sA" | sed -n '1{h;s/A/-sed-bearbeitet/};1p;${g;p}' |
|
Zeile-sed-bearbeitet ZeileA Nun weiter mit den Eläuterungen des langen Befehls: 2{s/l/g/g;p} bedeuted daß im Speicherplatz der zweiten Zeile der Binärterm des Buchstaben l in den Binärterm des Buchstaben g geändert wird. Dann gibt es die Anweisung daß dieser Speicherplatz zurückzuübersetzen ist. 3{s/ei/ah/g;p} bedeuted daß im Speicherplatz der dritten Zeile der Binärterm der Buchstaben ei in den Binärterm der Buchstaben ah geändert wird. Dann gibt es die Anweisung daß dieser Speicherplatz zurückzuübersetzen ist. ${g;p} bedeuted daß der holdspace an den Speicherplatz der bisherigen Zeilen angehängt wird und dieser Speicherplatz zurückzuübersetzen ist. ${g;s/A/22/g;p} bedeuted daß der Speicherplatz des holdspace erneut kopiert wird und in diesem kopierten holdspace der Binärterm des Buchstaben A in den Binärterm der Zeichen 22 geändert wird. Dann gibt es die Anweisung daß dieser Speicherplatz den bisherigen Zeilen angehängt wird und zurückzuübersetzen ist. Der holdspace bleibt dabei unverändert. Reicht der von einem Programm zugewiesene Speicherplatz für Zeichen nicht aus, so rechnet der Computer falsch. Hier ein Beispiel von der LibreOffice-Tabellenkalkulation. Zuerst eine richtige Rechnung: |

| Bekommen die Zahlenfolgen jetzt eine Ziffer mehr wird nicht mehr richtig gerechnet: |

|
Dieses Verhalten zeigt natürlich auch ein Taschenrechner. Tippe ich bei
meinem 10-stelligen Taschenrechner 4 000 000 000 000 -3 999 999 999 995 ein so erhalte ich das Ergebnis 1, da nach den 10 Stellen bei der Eingabe alles abgeschnitten wird. Der Eingabe-Speicherplatz reicht nur für 10-stellige Zahlen. Auch wenn sich die Eingabe-Zahlen richtig in den Taschenrechner eintippen lassen kann durch den begrenzten Speicherplatz beim Berechnen Fehler entstehen. Dazu als Beispiel die folgende mathematische Gleichheit |
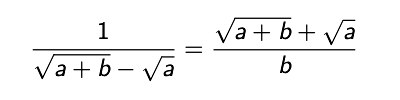
|
Dann berechnet mein Taschenrechner für a=1000 b=0,0001 das folgende Ergebnis 632471,0644 für die linke Seite 632455,5478 für die rechte Seite Natürlich wird Speicherplatz immer billiger und die Prozessor-Geschwindigkeit immer schneller so daß diese Grenze weiter nach oben verschoben werden kann. In bash rechnet bc im wissenschaftlichen Modus mit 20 Stellen nach dem Komma und liefert das Ergebnis 632455.54784506412808425309 für die linke Seite 632455.54784506377195240000 für die rechte Seite Läßt man bc mit 30 Stellen nach dem Komma rechnen so wird das Ergebnis 632455.547845063771956989692469767331 für die linke Seite 632455.547845063771956987612067320000 für die rechte Seite. |
|
Ein anderes Beispiel aus dem Internet. Man berechne 9.x4 - y4 + 2.y2 für x=10864 y=18817 bc im wissenschaftlichen Modus rechnet |
| echo "9*10864*10864*10864*10864-18817*18817*18817*18817+2*18817*18817" | bc -l |
|
1 und dies ist auch das richtige Ergebnis. Rechnet man bc mit Funktionen: |
| echo "9*e(l(10864)*4)-e(l(18817)*4)+2*e(l(18817)*2)" | bc -l |
|
1.00407896640976647920 Hier sieht man deutlich die Rundungsfehler. Läßt man bc mit 32 Stellen nach dem Komma rechnen so reduzieren sich die Rundungsfehler gewaltig 1.00000000000000063249167868060351 Eine Berechnung mit der Tabellenkalkulation liefert ein falsches Ergebnis: |
![]()
|
und wenn der Taschenrechner nicht mit 18-stelligen Zahlen umgehen kann
rechnet auch der Taschenrechner falsch. |