|
Programmfenster BLZ und
BIC Die Ausführungen der
vorherigen Seiten über Programmfenster werden hier weitergeführt. Bankleitzahlen.txt in dem Ordner ~/Bla Es soll nun gezeigt werden wie man über das Terminal (das man im Ordner ~/Bla öffnet) diese schon etwas umfangreiche txt-Datei bearbeiten kann um von einer vorgegebenen Bankleitzahl zu der entsprechenden BIC zu gelangen. Sicherlich kann man diese Datei mit einem Textprogramm öffnen und die Suchfunktion nutzen aber hier sollen Gedanken zum Terminal beschrieben werden. Dabei werden Terminal-Befehle wie Bausteine benutzt, überwiegend solche für sed. Eine schöne Liste dazu ist zu finden unter http://sed.sourceforge.net/sed1line_de.html Zunächst muß man die Bearbeitung der Datei durch das Terminal ermöglichen. Öffnet man diese Datei mit gedit und sucht nach08294Lößnitz so erhält man das Ergebnis. |

| Sucht man im Terminal mit grep |
| grep 08294Lößnitz Bankleitzahlen.txt |
| so erhält man kein Ergebnis. Eingabe im Terminal |
| cat Bankleitzahlen.txt |
| zeigt das Problem |

| Umlaute sind anders codiert und daher nicht zu identifizieren. Man kann sich die Codierung anschauen |
| file Bankleitzahlen.txt |
|
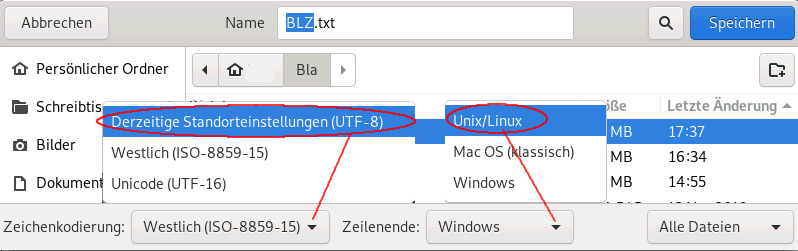
Bankleitzahlen.txt: ISO-8859 text, with CRLF line terminators Man kann die Datei Bankleitzahlen.txt mit gedit öffnen und bei Seichern unter kann man andere Codierung und anderes Zeilenende wählen. Also speichert man diese Datei unter BLZ.txt in dem Ordner ~/Bla ab und das Terminal bleibt weiterhin im Ordner ~/Bla geöffnet |
| Kontrolle |
| file BLZ.txt |
|
BLZ.txt: UTF-8 Unicode text Und jetzt werden die Umlaute gefunden |
| grep 08294Lößnitz BLZ.txt |
|
870540002Erzgebirgssparkasse 08294Lößnitz Erzgebirgssparkasse 58791
20056502U000000000
870962142Volksbank Chemnitz 08294Lößnitz Volksbank Chemnitz 98040 06056347U000000000 Es soll nach der BLZ gefiltert werden und die zugehörige BIC bestimmt werden, z.B. |
| grep 50852553 BLZ.txt |
| Die Ausgabe ist recht umfangreich mit vielen Leerzeichen und etlichen Zeilen. Aber man erkennt daß die letzte durch ein Leerzeichen getrennte Zeichenfolge die gesuchte BIC enthält. Also sucht man einen sed-Baustein der die letzte Zeichenfolge jeder Zeile heraussucht, getrennt durch das Trennzeichen LEERZEICHEN. |
| grep 50852553 BLZ.txt | sed 's/^.* //' |
|
55053HELADEF1GRG00007554U000000000 00005166U000000000 00005187U000000000 00005900U000000000 00006034U000000000 00007292U000000000 00007334U000000000 00007340U000000000 00007543U000000000 00007575U000000000 00007583U000000000 00008058U000000000 00008077U000000000 00008300U000000000 Die BIC ist hier nur in der ersten Zeile enthalten und es gibt nach der BIC noch 18 weitere Zeichen. Also sucht man einen sed-Baustein der die letzten 18 Zeichen jeder Zeile löscht |
| grep 50852553 BLZ.txt | sed 's/^.* //' | sed -r 's/.{18}$//' |
|
55053HELADEF1GRG Es gibt eine Menge von Leerzeilen. Also sucht man einen sed-Baustein der Leerzeilen löscht |
| grep 50852553 BLZ.txt | sed 's/^.* //' | sed -r 's/.{18}$//' | sed '/^$/d' |
|
55053HELADEF1GRG Jetzt sucht man einen sed-Baustein der die ersten 5 Zeichen löscht |
| grep 50852553 BLZ.txt | sed 's/^.* //' | sed -r 's/.{18}$//' | sed '/^$/d' | sed -r 's/^.{5}//' |
|
HELADEF1GRG Damit hat man die BIC zur BLZ 50852553 bestimmt. Bei allen diesen letzten Eingabe-Befehlen wurde immer die ganze BLZ-Datei durchsucht. Sicherlich ist ein Computer schnell aber trotzdem ist es vorteilhaft dem Computer etwas Arbeit abzunehmen. Man kann die Durchsuchung der BLZ-Datei für eine bestimmte BLZ nur einmal durchführen und das Ergebnis in eine Variable schreiben. Anschließend wird nur noch die Variable durchsucht oder bearbeitet. |
| einGABE=$(grep 50852553 BLZ.txt) |
|
Außerdem kann man diese Variable auch durch ein zenity-Eingabefenster
erzeugen, in das man dann z.B. 50852553 eintippt. |
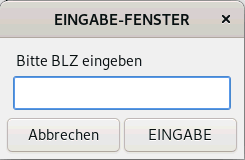
| einGABE=$(grep $(zenity --entry --ok-label "EINGABE" --title "EINGABE-FENSTER" --text " Bitte BLZ eingeben") BLZ.txt) |
| Aufruf der Variablen |
| echo "$einGABE" |
| Dann schreibt sich die BIC-Suche für 50852553 so |
| echo "$einGABE" | sed 's/^.* //' | sed -r 's/.{18}$//' | sed '/^$/d' | sed -r 's/^.{5}//' |
|
HELADEF1GRG Nun gibt es seltene Fälle bei denen das letzte Leerzeichen nicht zur gewünschten Abtrennung des BIC-Blockes führt |
| grep 13070000 BLZ.txt | grep Ribnitz | sed 's/^.* //' |
|
Ribnitz-Damgt27707DEUTDEBR13663046187U000000000
Deshalb ist das Löschen der ersten 5 Zeichen hier nicht sinnvoll. Man
könnte generell anders vorgehen: |
| echo "$einGABE" | sed -r 's/.{18}$//' | sed -r 's/.*(.{11})/\1/' | sed 's/ //g' | sed '/^$/d' |
|
HELADEF1GRG Aber auf diese Weise funktioniert es nicht immer. Hier eine andere BLZ: |
| einGABE=$(grep 54670024 BLZ.txt) |
| Mit der Variablen einGABE erzeugt durch 54670024: |
| echo "$einGABE" | sed -r 's/.{18}$//' | sed -r 's/.*(.{11})/\1/' | sed 's/ //g' | sed '/^$/d' |
|
DEUTDEDB546 DEUTDEDB552 DEUTDEDB548 Filtern lediglich nach der BLZ 54670024 zeigt daß es verschiedene Orte gibt |
| echo "$einGABE" |

| Der Name der Bank und die Namen der Orte enthalten Leerzeichen in unterschiedlicher Menge so daß das Trennzeichen LEERZEICHEN nicht sinnvoll verwendet werden kann. Aber einzelne Sinnblöcke sind durch mehrfach hintereinanderstehende Leerzeichen getrennt. Also verwendet man sed um 2 Leerzeichen in ein sonst nicht vorkommendes Trennzeichen # zu verwandeln. Anschließend verwendet man noch einen Baustein der mehrfach vorkommende Trennzeichen # in ein einzelnes # verwandelt |
| echo "$einGABE" | sed 's/ /#/g' | tr -s '#' |

| Nun stehen die Orte im 2. Feld, getrennt durch das Trennzeichen #. Also verwendet man einen cut-Baustein der dieses Feld heraustrennt |
| echo "$einGABE" | sed 's/ /#/g' | tr -s '#' | cut -f 2 -d '#' |
|
67433Neustadt an der Weinstraße 67085Bad Dürkheim 76829Landau in der Pfalz Nun sollen diese Orte einem zenity-Fenster übergeben werden damit eine Wahlmöglichkeit besteht. Es wird ein radiolist-Fenster gewählt: |
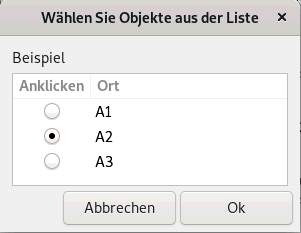
| zenity --list --text "Beispiel" --radiolist --column "Anklicken" --column "Ort" false A1 true A2 false A3 |
|
Die beispielhaften Orte A1 A2 A3 benötigen eine durch Leerzeichen
getrennte vorangestellte Eigenschaft false (leerer Auswahlkreis) oder true
(im voraus markierter Auswahlkreis). Daher dürfen die Orte keine
Leerzeichen enthalten denn sonst würde die Zuordnung der vorangestellten
Eigenschaft nicht mehr funktionieren. Es werden 3 Bausteine benutzt Leerzeichen werden durch Unterstriche ersetzt Eigenschaft false wird vorangestellt alles wird in eine Zeile geschrieben. Es wird auch gleich eine Variable erzeugt: |
| yA=$(echo "$einGABE" | sed 's/ /#/g' | tr -s '#' | cut -f 2 -d '#' | sed 's/ /_/g' | sed 's/^/ false /g' | tr -d '\n') |
| Aufruf der Variablen |
| echo "$yA" |
|
false _67433Neustadt_an_der_Weinstraße false _67085Bad_Dürkheim false
_76829Landau_in_der_Pfalz Dann wird diese Variable an das zenity-Fenster verfüttert, wobei gleich wieder eine neue Variable erzeugt wird |
| sTA=$(zenity --width 600 --height 300 --title "Details zur BIC-Bestimmung" --list --text "Es gibt mehrere Städte zur Auswahl" --radiolist --column "Anklicken" --column "Ort" $yA ) |
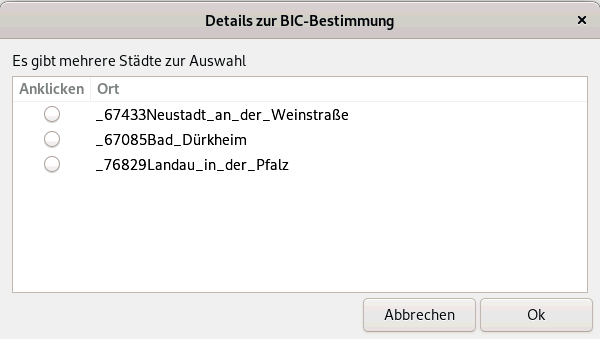
| Angenommen es wurde die oberste Möglichkeit gewählt. Aufruf der Variablen |
| echo $sTA |
|
_67433Neustadt_an_der_Weinstraße liefert die ausgewählte Stadt mit Unterstrichen statt Leerzeichen. Daher werden die Unterstriche wieder in Leerzeichen verwandelt und eine weitere Variable gebildet |
| sTADT=$(echo $sTA | sed 's/_/ /g') |
| Aufruf der Variablen |
| echo "$sTADT" |
|
67433Neustadt an der Weinstraße Nun wird nach der BLZ und auch nach der Stadt gefiltert |
| echo "$einGABE" | grep "$sTADT" |
|
546700241DB Privat- und Firmenkundenbank (Deutsche Bank PGK) 67433Neustadt an der Weinstraße DB PFK (Deutsche Bank PGK) 21198DEUTDEDB54663050170U000000000 Damit liegt wieder der anfangs beschriebene einzeilige Zustand vor und man kann die obigen Bausteine (ohne Löschung von Leerzeichen und Leerzeilen) benutzen. Am besten gleich in eine Variable schreiben |
| blZZ=$(echo "$einGABE" | grep "$sTADT" | sed -r 's/.{18}$//' | sed -r 's/.*(.{11})/\1/') |
| Die anfangs eingegebene BLZ kann man als Variable wiedergewinnen durch (sed-Baustein: alles löschen bis auf die ersten 8 Zeichen) |
| blZ=$(echo "$einGABE" | grep "$sTADT" | sed -r 's/(.{8}).*/\1/') |
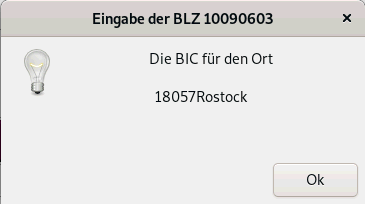
| Nun werden Variablen an ein zenity-Info-Fenster übergeben |
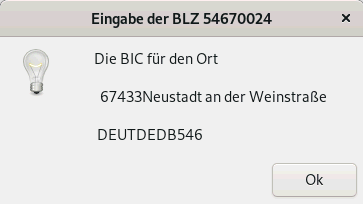
| zenity --info --width="280" --title="Eingabe der BLZ $blZ" --text "Die BIC für den Ort \n\n $sTADT \n\n $blZZ" |
|
Nun braucht man nur noch alles in ein script zu schreiben. Dabei wird untersucht wieviele Zeilen bei der
BIC-Bestimmung erzeugt werden. Mit wc -l läßt sich die Anzahl der Zeilen bestimmen. |
| nano ~/Bla/blz-BIC.sh |
| Eingabe in den Editor |
|
#!/bin/bash einGABE=$(grep $(zenity --entry --ok-label "EINGABE" --title "EINGABE-FENSTER" --text " Bitte BLZ eingeben") BLZ.txt) if [ $? -eq 1 ]; then exit fi yK=$(echo "$einGABE" | sed -r 's/.{18}$//' | sed -r 's/.*(.{11})/\1/' | sed 's/ //g' | sed '/^$/d') szZW=$(echo "$yK" | wc -l) if [ "$szZW" = 1 ]; then blZ=$(echo "$einGABE" | grep "$yK" | sed -r 's/(.{8}).*/\1/') zenity --info --width="280" --title="Eingabe der BLZ $blZ" --text "Die BIC ist \n\n $yK" else yA=$(echo "$einGABE" | sed 's/ /#/g' | tr -s '#' | cut -f 2 -d '#' | sed 's/ /_/g' | sed 's/^/ false /g' | tr -d '\n') sTA=$(zenity --width 600 --height 300 --title "Details zur BIC-Bestimmung" --list --text "Es gibt mehrere Städte zur Auswahl" --radiolist --column "Anklicken" --column "Ort" $yA ) if [ $? -eq 1 ]; then exit fi sTADT=$(echo $sTA | sed 's/_/ /g') blZZ=$(echo "$einGABE" | grep "$sTADT" | sed -r 's/.{18}$//' | sed -r 's/.*(.{11})/\1/') blZ=$(echo "$einGABE" | grep "$sTADT" | sed -r 's/(.{8}).*/\1/') zenity --info --width="280" --title="Eingabe der BLZ $blZ" --text "Die BIC für den Ort \n\n $sTADT \n\n $blZZ" fi |
| Nun muß man das script ausführbar machen |
| chmod +x ~/Bla/blz-BIC.sh |
|
Die Datei BLZ.txt und das script blz-BIC.sh müssen im gleichen Ordner liegen. Trotzdem kann es vorkommen daß für einen Ort keine passende BIC gefunden wird. |