|
doppelte Zeichenfolgen finden Generell gilt bei den weißen Textstellen auf dieser Seite: Man fügt die
Zeichenfolge aus dem weißen Feld bei dem blinkenden Cursor des Terminals
ein - dann drückt man die Eingabetaste. |
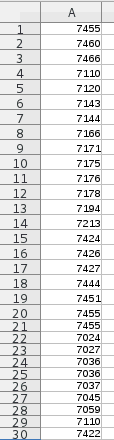
|
so kann man diese Zellen mit
den Zahlen kopieren und mit einem Texteditor (z.B. gedit) in eine
txt-Datei einfügen. Dieser gibt man z.B. den Namen ttspalte.txt im Ordner ~/ Diese txt-Datei kann man im Terminal öffnen mit |
| cat ~/ttspalte.txt |
| Man kann mit |
| cat ~/ttspalte.txt | sed 's| ||g' | sort | uniq |
|
mögliche Leerzeichen
entfernen, die Zahlen sortieren, doppelte Zahlen entfernen (dies
funktioniert mit uniq nur wenn zuvor sortiert wurde). Dies ist auch genauso möglich mit |
| sort ~/ttspalte.txt | sed 's| ||g' | uniq |
| Man kann diese bearbeiteten Zahlen im Terminal kopieren und in die Tabelle einfügen und hat damit alle doppelten Zahlen entfernt. |
| Man kann die Zahlen ausgeben lassen die doppelt (oder mehrfach) vorkommen |
| sort ~/ttspalte.txt | sed 's| ||g' | uniq -d |
|
7036 7110 7455 Man kann die doppelten (oder mehrfachen) Zahlen mit der entsprechenden Mehrfach-Anzahl ausgeben lassen |
| sort ~/ttspalte.txt | sed 's| ||g' | uniq -D |
|
7036 7036 7110 7110 7455 7455 7455 Man kann auszählen lassen wie oft die jeweiligen Zeichenfolgen vorkommen (es wird die Anzahl in einer Spalte davorgeschrieben) |
| sort ~/ttspalte.txt | sed 's| ||g' | uniq -c |
|
Man kann alles wieder neu
sortieren lassen -r (umgekehrte Reihenfolge) -n (Sortierung nach den Zahlen der ersten Spalte) |
| sort ~/ttspalte.txt | sed 's| ||g' | uniq -c | sort -rn |
|
3 7455 2 7110 2 7036 ... Damit hat man die Zahlen die am meisten vorkommen ganz oben. Man kann diese Anzahl-Sortierung bei den Lotto-Zahlen der letzten Wochen durchführen. Da statistisch jede Zahl die gleiche Wahrscheinlichkeit hat gezogen zu werden, kann man beim Tippen die Zahlen auswählen, die in den letzten Wochen am wenigsten vorgekommen sind. Möchte man nach Zahlen der Spalte 2 sortieren so benutzt man sort -r -n -k 2,2 sort -n -k 2,2 Bei einer Sortierung nach Zahlen der Spalte 3 sort -r -n -k 3,3 sort -n -k 3,3 Wenn man Spalten nach Buchstaben sortieren möchte so läßt man -n weg. Hat man nun weitere Zahlen in einer Zeile vorliegen (z.B. aus einem e-mail-Programm) 7027, 7059, 7110, 7143, 7287, 7292, 7313, 7389, 7455, 7469, 7593, 7606, 7746, 7770, 7804, 7946, 7971, 7024 7479 7535 7772 so kann man diese Zahlen kopieren und mit einem Texteditor (z.B. gedit) in eine txt-Datei einfügen. Dieser gibt man z.B. den Namen ttzeile.txt im Ordner ~/ Diese Zahlen sollen nun senkrecht untereinander geschrieben und der Datei ~/ttspalte.txt hinzugefügt werden |
| cat ~/ttzeile.txt | tr -s ' ' | sed 's| |\n|g' | sed 's|,||g' >> ~/ttspalte.txt |
|
Zuerst werden mögliche mehrfach
hintereinander vorkommende Leerzeichen auf ein Leerzeichen reduziert, dann
wird ein Leerzeichen in einen Zeilenumbruch verwandelt, dann werden
möglicherweise vorkommende Kommas gelöscht, und alles der Datei ~/ttspalte.txt
hinzugefügt. Dann kann man mit sort ~/ttspalte.txt | sed 's| ||g' | uniq wieder sortieren und doppelte Zahlen entfernen. Das alles funktioniert auch mit Listen von e-mail-Adressen oder Worten ohne Leerzeichen. Wenn die Zahlen ohne Leerzeichen in folgender Form vorliegen 7027,7059,7110,7143,7287,7292,7313,7389,7455,7469,7593,7606,7746,7770, so kopiert man diese Zahlen in die Datei ~/ttzeile.txt und ändert das Komma in einen Zeilenumbruch und fügt alles der Datei ~/ttspalte.txt hinzu |
| cat ~/ttzeile.txt | sed 's|,|\n|g' >> ~/ttspalte.txt |
| Umgekehrt kann man eine Zahlen-Spalte in eine Zeile umschreiben mit: |
| cat ~/ttspalte.txt | sed 's|$|, |g' | tr -d '\n' |
|
7027, 7059, 7110, 7143,
7287, 7292, 7313, 7389, 7455, 7469, 7593, 7606, 7746, 7770, Und man kann auch doppelte Worte in einem Textabschnitt ausfindig machen, etwa im Text: Das alles funktioniert auch mit mit Listen von e-mail-Adressen oder Worten ohne ohne Leerzeichen. Man kopiert den Text-Absatz mit einem Texteditor (z.B. gedit) in eine txt-Datei. Dieser gibt man z.B. den Namenttabsatz.txt im Ordner ~/ Dann schreibt man den Text in eine Zeile indem man die Zeilenumbrüche entfernt, dann werden mehrfache Leerzeichen zu einem Leerzeichen reduziert, dann werden Leerzeichen durch Zeilenumbrüche ersetzt (sortieren darf man natürlich nicht, denn der Sinn des Textes würde damit zerstört). Zunächst kann man untersuchen ob doppelte Worte vorhanden sind: |
| cat ~/ttabsatz.txt | tr -d '\n' | tr -s ' ' | sed 's| |\n|g' | uniq -D |
|
mit mit ohne ohne Dann kann man doppelte Worte entfernen und um den Text-Absatz wieder in eine lesbare Zeile zu schreiben wird zuerst am Ende jedes Wortes (jeder Zeile, die nur aus einem Wort besteht) ein Leerzeichen angefügt, dann alles in eine Zeile geschrieben: |
| cat ~/ttabsatz.txt | tr -d '\n' | tr -s ' ' | sed 's| |\n|g' | uniq | sed 's|$| |g' | tr -d '\n' |
| Man kann den korrigierten Text im Terminal kopieren und in ein writer-Dokument einfügen oder den Ursprungstext ersetzen: |

| Oder den korrigierten Text in eine neue txt-Datei schreiben |
| cat ~/ttabsatz.txt | tr -d '\n' | tr -s ' ' | sed 's| |\n|g' | uniq | sed 's|$| |g' | tr -d '\n' > ~/ttabsatz-neu.txt |
Hat man z.B. eine Namensliste (Worte mit Leerzeichen) so kann man die Leerzeichen ersetzen durch _ |
| cat ~/ttnamen.txt | sed 's| |_|g' > ~/ttnamen_ohne_leerz.txt |
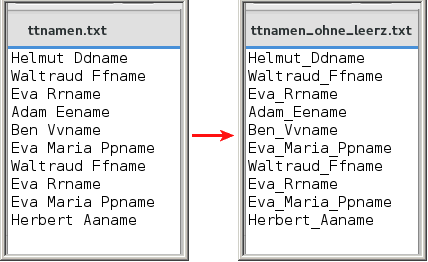
| Dann kann man doppelte Namen sehen mit |
| cat ~/ttnamen.txt | sed 's| |_|g' | sort | uniq -D | sed 's|_| |g' |
|
Eva Maria Ppname Eva Maria Ppname Eva Rrname Eva Rrname Waltraud Ffname Waltraud Ffname Man kann doppelte Namen löschen. Und das letzte vorkommende Leerzeichen kann man in das Zeichen ; umwandeln: |
| cat ~/ttnamen.txt | sed 's| |_|g' | sort | uniq | sed 's|_| |g' | sed 's|\(.*\) |\1;|' |
| oder in eine Datei schreiben: |
| cat ~/ttnamen.txt | sed 's| |_|g' | sort | uniq | sed 's|_| |g' | sed 's|\(.*\) |\1;|' > ~/ttnamen_VN_NN.txt |
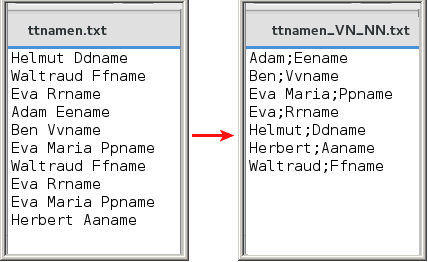
|
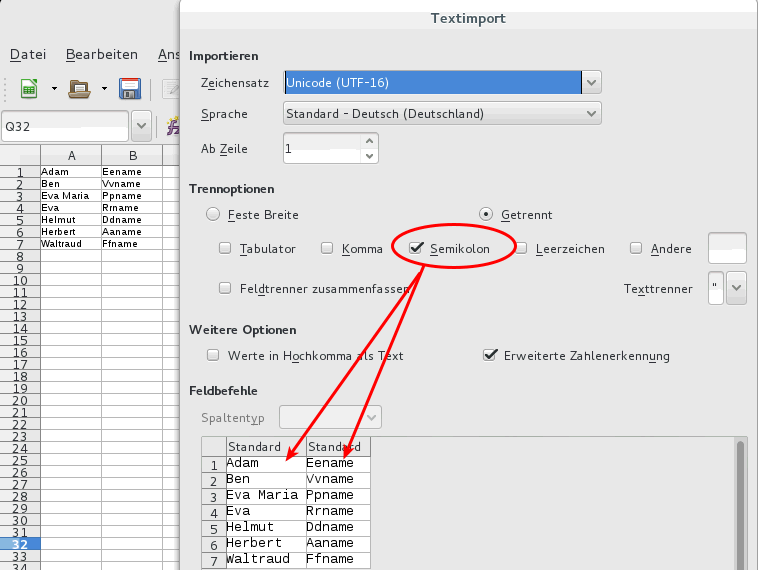
Dann kann man diese Namen in
eine Tabelle einfügen wobei Vornamen mit Leerzeichen und Vornamen ohne Leerzeichen in der gleichen Spalte erscheinen, sofern das Trennzeichen ; beim Import ausgewählt wird: |
| Man kann mit cut und Wahl des Trennzeichens ; auch einzelne Felder herausschneiden: |
| cat ~/ttnamen_VN_NN.txt | cut -d';' -f1 |
|
Adam Ben Eva Maria Eva Helmut Herbert Waltraud oder in eine Datei schreiben: |
| cat ~/ttnamen_VN_NN.txt | cut -d';' -f1 > ~/ttnamen_VN.txt |
| Oder dem herausgeschnittenen Feld noch etwas hinzufügen: |
| cat ~/ttnamen_VN_NN.txt | cut -d';' -f2 | sed 's|$|:|g' |
|
Eename: Vvname: Ppname: Rrname: Ddname: Aaname: Ffname: oder in eine Datei schreiben: |
| cat ~/ttnamen_VN_NN.txt | cut -d';' -f2 | sed 's|$|:|g' > ~/ttnamen_NN.txt |
| Dann kann man diese beiden Spalten wieder zusammenkleben: |
| paste ~/ttnamen_NN.txt ~/ttnamen_VN.txt > ~/ttnamen_NN_VN.txt |
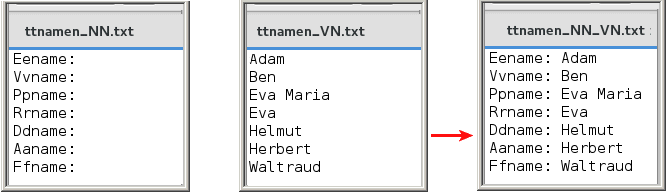
|
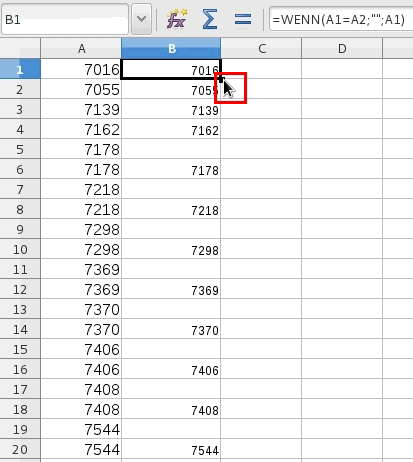
Noch eine Anmerkung wie man
bei einer Spalte doppelte Einträge in der Tabellenkalkulation
entfernen kann. Angenommen es liegen in der Spalte A Einträge vor.
Dann sortiert man diese Einträge. Anschließend schreibt man in
die Zelle B1 =WENN(A1=A2;"";A1) Dann fährt man mit der Maus auf das Quadrat unten rechts (bei der Markierung von B1) bis sich der Mauszeiger in ein Kreuz verwandelt. Dann macht man einen Doppelklick auf das Quadrat. Damit wird die Formel (entsprechend der jeweiligen Zeile) auf die ganze Spalte B erweitert, solange Werte in der Spalte A vorhanden sind. Kommt ein Eintrag doppelt vor so erscheint eine leere Zelle, ansonsten der Wert aus der A-Spalte. Jetzt sortiert man Spalte B, damit alle leeren Zellen nach unten rutschen. Die Spalte A mit den doppelten Zeichenfolgen kann man dann löschen. |