|
Tabelle aus PDF Generell gilt bei den weißen Textstellen auf dieser Seite: Man fügt die
Zeichenfolge aus dem weißen Feld bei dem blinkenden Cursor des Terminals
ein - dann drückt man die Eingabetaste. Manchmal möchte man eine Tabelle aus einem PDF herauskopieren, damit man diese weiterverarbeiten kann. Sofern man die Zeichen kopieren kann (und es sich nicht um ein Bild handelt) kann man das Terminal zu Hilfe nehmen. Hier ein Beispiel aus einem PDF bei dem die Zeichen markiert sind |

|
Kopieren dieser Zeichen im PDF und einfügen in gedit: |
01.02. 1 |
Bei Debian 11
Man kann die PDF-Datei mit dem Dokumentenbetrachter öffnen und die
markierten Tabellenzeichen in gedit einfügen. Man erhält in gedit
die Zeichen wie links gezeigt.
Bei Debian 12
Das gleiche Vorgehen führt jetzt zu den Zeichen wie rechts gezeigt. Alle
Leerzeichen sind verschwunden. Man kann die PDF-Datei mit firefox öffnen
und die markierten Zeichen in gedit einfügen. Dann erhält man in
gedit die Zeichen wieder wie links gezeigt.Wenn die Leerzeichen nicht mehr vorhanden sind funktionieren natürlich die folgenden Schritte nicht mehr. |
01.02.1 |
|
Dann wird diese Datei als hG.txt abgespeichert und das Terminal in dem Ordner
geöffnet in dem die hG.txt liegt. Die Datei enthält Infos zu Datum,
Preis und Menge. Man möchte Gesamt-Mengenzahlen pro Tag und Mengen pro
Artikel über alle Tage. Man kann die Datei im Terminal aufrufen durch |
| cat hG.txt |
|
Die gewünschten Mengen-Zahlen stehen pro Zeile an letzter Stelle -
meistens jedenfalls. Es werden die folgenden Bausteine verwendet: es wird am Ende jeder Zeile _ angefügt es wird das zweite Feld mit Tennzeichen LEERZEICHEN ausgeschnitten Es werden die Zeilen in denen , vorkommt gelöscht und ersetzt durch eine Zeile mit dem Zeichen # Es werden alle Zeilen in eine Zeile geschrieben es wird das Zeichen # in einen Zeilenumbruch verwandelt |
| cat hG.txt | sed 's/$/_/g' | cut -f 2 -d ' ' | sed '/,/ c #' | tr -d '\n' | sed 's/#/\n/g' |
|
1_28_2_3_0_1_ 2_8_3_1_1_0_ 2_31_8_11_3_0_ 2_18_4_3_4_0_ Diese Zahlen kann man im Terminal kopieren und in eine Tabelle einfügen (Einfügen - unformatierter Text) wobei man als Trennoption _ verwendet |
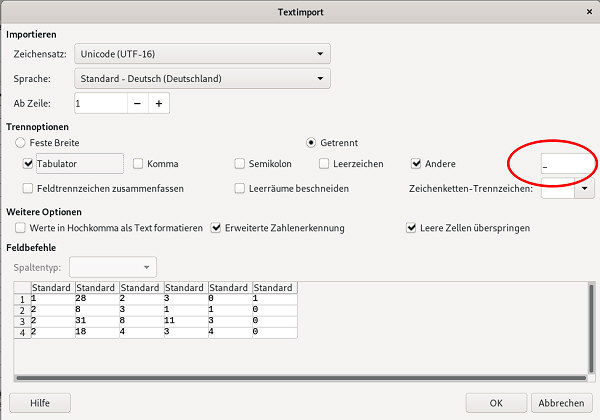
|
Dann kann man schnell Zeilensummen (Gesamt-Mengenzahlen pro Tag) und Spaltensummen (Mengen pro Artikel über alle Tage) bilden |
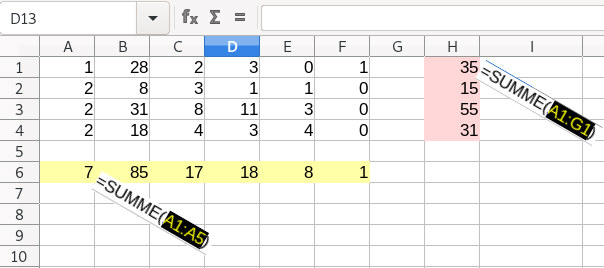
|
Es mag sein daß für andere Tabellen andere Terminal-Bausteine verwendet
werden müssen. Wenn man das Datum mit ausgeben möchte (z.B. für eine Tagesstatistik) kann man einen Baustein voranstellen, der bei allen Zeilen in denen ein Punkt vorkommt LEERZEICHEN durch _ ersetzt sed '/\./ s/ /_/' |
| cat hG.txt | sed '/\./ s/ /_/' | sed 's/$/_/g' | cut -f 2 -d ' ' | sed '/,/ c #' | tr -d '\n' | sed 's/#/\n/g' |
|
01.02._1_28_2_3_0_1_ 03.02._2_8_3_1_1_0_ 04.02._2_31_8_11_3_0_ 05.02._2_18_4_3_4_0_ Es ist etwas schwieriger wenn die Tabelle nur Zahlen enthält, ohne daß man Punkte (vom Datum) oder Komma (vom Preis) als Bearbeitungspunkte nutzen könnte: |

|
Kopieren dieser Zeichen im PDF und einfügen in gedit:
1 |
| cat hH.txt | sed 'N;N;N;N;N;s/\n/_/g' |
|
1_28_2_3_0_1 2_8_3_1_1_0 2_31_8_11_3_0 2_18_4_3_4_0 Diese Zahlen kann man im Terminal kopieren und in eine Tabelle einfügen (Einfügen - unformatierter Text) wobei man als Trennoption _ verwendet |
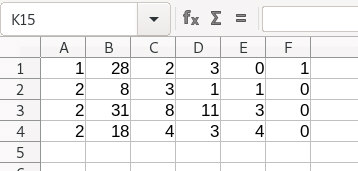
|
Man kann diese Block-Bildung natürlich auch bei obigem 1. Beispiel
(also hG.txt) verwenden. Dazu kann man folgende Bausteine benutzen sämtliche LEERZEICHEN werden durch einen Zeilenumbruch ersetzt alle Zeilen die Komma oder Punkt enthalten werden gelöscht Gruppierung der Zahlen in 6-er-Blocks cat hG.txt | sed 's/ /\n/g' | sed '/[,.]/ d' | sed 'N;N;N;N;N;s/\n/_/g' Ersetzt man das Trennzeichen _ durch + und verfüttert das Ergebnis an das Rechenprogramm bc so erhält man auch gleich die Gesamt-Mengenzahlen pro Tag |
| cat hG.txt | sed 's/ /\n/g' | sed '/[,.]/ d' | sed 'N;N;N;N;N;s/\n/+/g' | bc |
|
35 15 55 31 Man kann auch bei hG.txt den Gesamtbetrag (Menge mal Preis) aller Artikel berechnen. Dazu kann man zunächst das Datum entfernen. Also sucht man einen sed-Baustein der die letzte Zeichenfolge jeder Zeile heraussucht, getrennt durch das Trennzeichen PUNKT (der maskiert wird) \. allerdings nur in Zeilen in denen ein PUNKT (der maskiert wird) vorkommt |
| cat hG.txt | sed '/\./s/^.*\.//' |
1 Nun wählt man einen sed-Baustein der am Schluß jeder Zeile ein MULTIPLIKATIONSZEICHEN anfügt, allerdings nur wenn in der Zeile ein LEERZEICHEN vorhanden ist |
| cat hG.txt | sed '/\./s/^.*\.//' | sed '/ /s/$/*/' |
| Dann ersetzt man alle LEERZEICHEN durch ein Additionszeichen und schreibt alles in eine Zeile |
| cat hG.txt | sed '/\./s/^.*\.//' | sed '/ /s/$/*/' | sed 's/ /+/g' | tr -d '\n' |
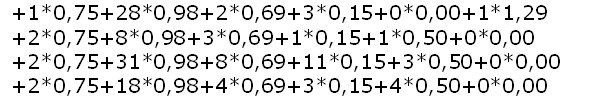
|
Das sieht schon recht gut aus: alle Mengen mal Preis werden aufaddiert. Aber man kann diese Ausgabe noch nicht an bc verfüttern. Denn bc kann nur rechnen wenn anstelle von , ein PUNKT (der maskiert wird) steht. Also nimmt man einen sed-Baustein der jedes , in \. verwandelt. Außerdem stolpert bc über das allererste + das man mit einem weiteren sed-Baustein entfernt. Und noch ein Stolperstein muß beseitigt werden, denn bc kapituliert wenn nicht am Ende der Zeile ein Zeilenumbruch-Zeichen vorhanden ist. Also: |
| cat hG.txt | sed '/\./s/^.*\.//' | sed '/ /s/$/*/' | sed 's/ /+/g' | tr -d '\n' | sed 's/,/\./g' | sed 's/^+//' | sed 's/$/\n/' | bc |
|
108.27 Damit hat man den Gesamtbetrag (Menge mal Preis) aller Artikel berechnet. Noch eine Bemerkung zum Rechenprogramm bc: Wenn eine Rechenoperation mit MINUSZEICHEN beginnt, rechnet bc |
| echo -3.1*2 | bc |
|
-6.2 Wenn eine Rechenoperation mit PLUSZEICHEN beginnt, rechnet bc allerdings nicht |
| echo +3.1*2 | bc |
|
(standard_in) 1: syntax error Mit KOMMAZAHLEN rechnet bc schon gar nicht. Und oben hat sich gezeigt daß bc auch nicht rechnet wenn am Ende der Zeile ein Zeilenumbruch fehlt. Man kann versucht sein bc etwas zu verändern um solche Fälle zu umgehen. Man kann mit alias eine Abkürzung festlegen (vielleicht bC) und damit diese Abkürzung im System bekannt bleibt schreibt man diese in die Datei ~/.bashrc Man vergleiche die Seite mit fbpanel |
| alias bC='pr -t | sed "s/,/\./g" | sed "s/^+//" | bc' |
|
Wenn man also zurückspringt an die Stelle: Das sieht schon recht gut aus: alle Mengen mal Preis werden aufaddiert. Dann kann man diese Ausgabe an bC verfüttern. |
| cat hG.txt | sed '/\./s/^.*\.//' | sed '/ /s/$/*/' | sed 's/ /+/g' | tr -d '\n' | bC |
|
108.27 Damit hat man den Gesamtbetrag (Menge mal Preis) aller Artikel berechnet. Und natürlich kann man auch sonst mit KOMMAZAHLEN rechnen |
| echo +3,1*2 | bC |
|
6.2 auch |
| echo +28/0,98 | bC -l |
|
28.57142857142857142857 Wenn man nochmals zurückspringt an die Stelle: Das sieht schon recht gut aus: alle Mengen mal Preis werden in EINER ZEILE aufaddiert. Nicht so wie das Foto nahelegt: mit 6 Multiplikationen in 4 ZEILEN mit jeweils einem Zeilenumbruch am Ende. Aber man kann eine solche Anordnung bekommen, bevor man alles in eine Zeile schreibt, durch Gruppierung in 7-er-Blocks wobei der Zeilenumbruch durch NICHTS ersetzt wird (also Zeilenumbruch gelöscht wird). Anschließend an bC verfüttern: |
| cat hG.txt | sed '/\./s/^.*\.//' | sed '/ /s/$/*/' | sed 's/ /+/g' | sed 'N;N;N;N;N;N;s/\n//g' | bC |
|
31.31 12.06 40.55 24.35 Damit hat man die Tagesumsätze aller Artikel berechnet. Um die Verkaufszahlen einzelner Artikel über alle Tage zu bestimmen muß man die Spalten betrachten. Man könnte durch das Zeichen + die in Spalten notierten Artikel trennen. Aber das + wird noch bei der Addition gebraucht. Daher wird ein Trennzeichen # eingefügt, vor jedem + allerdings nicht bei dem ersten vorkommenden +. Dies wird gleich in eine Variable geschrieben. |
| sPA=$(cat hG.txt | sed '/\./s/^.*\.//' | sed '/ /s/$/*/' | sed 's/ /+/g' | sed 'N;N;N;N;N;N;s/\n//g' | sed 's/+/#+/g;s/^#//') |
| echo "$sPA" |
|
+1*0,75#+28*0,98#+2*0,69#+3*0,15#+0*0,00#+1*1,29 +2*0,75#+8*0,98#+3*0,69#+1*0,15#+1*0,50#+0*0,00 +2*0,75#+31*0,98#+8*0,69#+11*0,15#+3*0,50#+0*0,00 +2*0,75#+18*0,98#+4*0,69#+3*0,15#+4*0,50#+0*0,00 Damit lassen sich mit cut über das Trennzeichen # die einzelnen Artikel trennen. Z.B. für den 2.Artikel. Anschließend alles in eine Zeile schreiben und an bC verfüttern |
| echo "$sPA" | cut -f 2 -d '#' | tr -d '\n' | bC |
|
83.30 Dies ist der Gesamtverkauf des 2. Artikels über alle Tage. Um dies gleich für alle Artikel zu machen kann man eine for-Schleife nutzen, die allerdings die Anzahl der Artikel benötigt. Man kann die Spalten-ANZahl (SpANZ) bestimmen (Anzahl der Artikel) |
| SpANZ=$(echo "$sPA" | head -n 1 | sed 's/#/\n/g' | wc -l) |
|
Dann kann man die Schliefe laufen lassen
|
| for ((i=1; i<="$SpANZ"; i++)); do echo "$sPA" | cut -d "#" -f "$i" | tr -d "\n" | bC ; done |
|
5.25 83.30 11.73 2.70 4.00 1.29 Damit hat man den Gesamtverkauf aller 6 Artikel über alle Tage. Man kann "$sPA" als "Tabelle" verstehen deren "Tabellenzellen" durch das Zeichen # und den Zeilenumbruch getrennt sind. Eine andere Möglichkeit ist es daher bei der "Tabelle" "$sPA" die Zeilen und Spalten zu vertauschen, die "Tabelle" zu transponieren. Dazu werden zunächst alle "Tabellen-Elemente" untereinandergeschrieben mit # wird in Zeilenumbruch verwandelt dann wird eine neue Sortierung in $(echo "$sPA" | wc -l) Spalten erzeugt. $(echo "$sPA" | wc -l) ist die Anzahl der Zeilen, hier 4. Man hätte in diesem Fall schreiben können pr -t -s" " -4 anschließend wird alles an bC verfüttert |
| echo "$sPA" | sed 's/#/\n/g' | pr -t -s" " -"$(echo "$sPA" | wc -l)" | bC |
|
5.25 83.30 11.73 2.70 4.00 1.29 Damit hat man wiederum den Gesamtverkauf aller 6 Artikel über alle Tage. Man kann die Gruppierung von Zahlen in Blocks auch sehr komfortabel mit pr durchführen. Z.B. die Zeilengruppierung in 6-er-Blocks mit dem Trennzeichen + bei hH.txt |
| cat hH.txt | pr -at -s"+" -6 |
|
1+28+2+3+0+1 2+8+3+1+1+0 2+31+8+11+3+0 2+18+4+3+4+0 Oder die Spaltengruppierung in 4-er-Blocks mit dem Trennzeichen + bei hH.txt was die darüberstehende "Tabelle" transponiert |
| cat hH.txt | pr -t -s"+" -4 |
|
1+2+2+2 28+8+31+18 2+3+8+4 3+1+11+3 0+1+3+4 1+0+0+0 Verfüttern an bc |
| cat hH.txt | pr -t -s"+" -4 | bc |
|
7 85 17 18 8 1 Damit hat man die Mengen pro Artikel über alle Tage. |