|
read tabelle Es
wird das leicht veränderte Rechenprogramm bC von der Seite Mit dem Programm read kann man Eingaben lesen. Dazu wird eine Datei in dem Ordner ~/Bla erzeugt |
| gedit ~/Bla/hK.txt |
| Eingabe in den Editor |
|
1:28:2:3:0:1 2:8:3:1:1:0 2:31:8:11:3:0 2:18:4:3:4:0 |
| Dann Speichern. Danach wird aus dieser Datei eine Variable erzeugt, dazu das Terminal in ~/Bla öffnen und auch weiterhin in ~/Bla geöffnet lassen |
| dN=$(cat hK.txt) |
| oder auch |
| dN=$(<hK.txt) |
|
read liest jeweils eine Zeile. Hinter dem read gibt man eine Zeichenfolge ohne LEERZEICHEN ein. Diese Zeichenfolge wird zu einer Variablen mit dem Inhalt der ersten Zeile. |
| read a < hK.txt |
| echo "$a" |
|
1:28:2:3:0:1 auch |
| read Zeile <<< "$dN" |
| echo "$Zeile" |
|
1:28:2:3:0:1 Auf der Seite Debian Gnome Programmfenster Sonderzeichen wurden 30 Variablen definiert: zS01=$(cat ~/.meine_sonderzeichen/zS01.txt | cut -c 1-10 | head -n 1) for i in {01..30}; do read zS$i <<< $(cat ~/.meine_sonderzeichen/zS$i.txt | cut -c 1-10 | head -n 1); done Nun wird es interessant: Man kann read ein Trennzeichen mit IFS vorgeben und dann trennt read die Zeile in "Worte" auf und man kann read mehrere Zeichenfolgen getrennt durch LEERZEICHEN vorgeben und diese werden als Variablen den "Worten" zugeordnet. Das erste Wort der Eingabe wird der ersten Variablen zugewiesen, das zweite Wort der zweiten Variablen, und so weiter. Wenn mehr Variablen angegeben sind, als die Eingabe Worte enthält, dann sind die überzähligen Variablen leer. Wenn die Eingabe mehr Worte enthält, als Variablen angegeben sind, dann erhält die letzte Variable den ganzen Rest der Eingabezeile. |
| IFS=: read a1 a2 a3 <<< "$dN" |
| echo "$a3 da diese Variable den Rest aufnimmt, $a2 danach $a1" |
|
2:3:0:1 da diese Variable den Rest aufnimmt, 28 danach 1 Auf der Seite Debian Gnome Programmfenster verbesserte Suchfunktion wurde aus der Variablen "$yA" vier andere Variablen erzeugt: suchTXT=$(echo "$yA" | cut -f 1 -d '|') suchWORD=$(echo "$yA" | cut -f 3 -d '|') suchLIB=$(echo "$yA" | cut -f 2 -d '|') suchXLS=$(echo "$yA" | cut -f 4 -d '|') Dies kann man mit read so machen IFS="|" read suchTXT suchLIB suchWORD suchXLS <<< "$yA" Mit einer while-Schleife kann man noch mehr erreichen |
| while IFS=: read Spalte1 Spalte2 A B C Spalte6; do echo "$Spalte1 -> $Spalte6"; done <<< "$dN" |
|
1 -> 1 2 -> 0 2 -> 0 2 -> 0 Damit lassen sich Spalten vertauschen oder mehrfach ausgeben. |
| while IFS=: read Spalte1 Spalte2 A B C Spalte6; do echo "$C $C $B $B"; done <<< "$dN" |
|
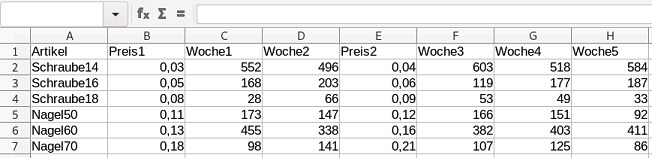
0 0 3 3 1 1 1 1 3 3 11 11 4 4 3 3 Es soll eine Tabelle aus einer Tabellenkalkulation zugrundegelegt werden |
|
Die Spalten sind beschriftet, wobei WocheN die Verkaufszahlen in der Woche
N ausgibt. Bevor die Woche 1 beginnt kostet der Artikel Preis1, nach der
Woche 2 (vor Beginn der Woche 3) wird der Preis2 angesetzt. Man kann die
Tabellenzellen kopieren und in gedit einfügen. Der blinkende Cursor
erscheint in einer neuen Zeile. Daher drückt man die Rückwärtstaste
damit der blinkende Cursor hinter dem letzten Zahlenwert erscheint.
Ansonsten hat man eine zusätzliche LEERZEILE, die man entfernen müßte. Man speichert die Datei unter sa.txt im Ordner ~/Bla ab und das Terminal bleibt weiterhin in ~/Bla geöffnet. Aufruf im Terminal. |
| cat sa.txt |
Artikel Preis1 Woche1 Woche2 Preis2 Woche3 Woche4 Woche5 Schraube14 0,03 552 496 0,04 603 518 584 Schraube16 0,05 168 203 0,06 119 177 187 Schraube18 0,08 28 66 0,09 53 49 33 Nagel50 0,11 173 147 0,12 166 151 92 Nagel60 0,13 455 338 0,16 382 403 411 Nagel70 0,18 98 141 0,21 107 125 86 Wenn die Werte im Terminal nicht so schön getrennt erscheinen könnte man eine optische Formatierung durchführen |
| cat sa.txt | column -t |
|
Aber das ist nur Kosmetik. Nachweis daß das Trennzeichen ein Tabulator-Zeichen \t ist |
| cat sa.txt | sed 's/\t/\\t/g' |
|
Artikel\tPreis1\tWoche1\tWoche2\tPreis2\tWoche3\tWoche4\tWoche5 Das Tabulatorzeichen wird von read ohne weiteres akzeptiert genauso wie das LEERZEICHEN (man braucht keine IFS zu setzen) und es sollen die von read eingelesenen Variablen den Spaltenbezeichnungen aus der Tabellenkalkulation entsprechen. Man möchte den Gesamtpreis berechnen, also kurz mit den Spalten-Bezeichnungen aus dem Tabellenprogramm (C+D)xB+(F+G+H)xE |
| while read A B C D E F G H; do echo "($C+$D)*$B+($F+$G+$H)*$E"; done < sa.txt |
|
(Woche1+Woche2)*Preis1+(Woche3+Woche4+Woche5)*Preis2 (552+496)*0,03+(603+518+584)*0,04 (168+203)*0,05+(119+177+187)*0,06 (28+66)*0,08+(53+49+33)*0,09 (173+147)*0,11+(166+151+92)*0,12 (455+338)*0,13+(382+403+411)*0,16 (98+141)*0,18+(107+125+86)*0,21 Mit dem Tabellenprogramm könnte dies so aussehen |
![]()
|
Nun kann man die erste Zeile löschen und alles an bC (Seite: Debian Gnome
Tabelle aus PDF) verfüttern. |
| while read A B C D E F G H; do echo "($C+$D)*$B+($F+$G+$H)*$E"; done < sa.txt | sed '1d' | bC |
|
99.64 47.53 19.67 84.28 294.45 109.80 Aber man kann auch die sa.txt mit sed einlesen und die erste Zeile löschen und dies als Variable an read übergeben. Dann kann man auch innerhalb der while-Schleife rechnen. |
| while read A B C D E F G H; do GS=$(echo "($C+$D)*$B+($F+$G+$H)*$E" | bC); GM=$(echo "$C+$D+$F+$G+$H" | bC); echo "$A Verkaufsmenge:$GM Gesamtbetrag:$GS - Preis wurde von $B auf $E geändert"; done <<< $(sed '1d' < sa.txt) |
|
Schraube14 Verkaufsmenge:2753 Gesamtbetrag:99.64 - Preis wurde von 0,03
auf 0,04 geändert Oder auch |
| while read A B C D E F G H; do GS=$(echo "($C+$D)*$B+($F+$G+$H)*$E" | bC); GSS=$(echo "($C+$D+$F+$G+$H)*$B" | bC); PR=$(echo "$GS*10000/$GSS-10000" | bC | sed 's/\([0-9][0-9]\)$/,\1/'); echo "$A BAR-Verkauf:$GS ohne Preiserhöhung nur $GSS gewesen, Verkaufs-PLUS:$PR%"; done <<< $(sed '1d' < sa.txt) |
|
Schraube14 BAR-Verkauf:99.64 ohne Preiserhöhung nur 82.59 gewesen,
Verkaufs-PLUS:20,64% Innerhalb der while-Schleife wird jeweils eine Zeile bearbeitet so daß z.B. die Variable $GM sich mit jeder Zeile verändert. Aber man kann eine NEUE Variable $GM außerhalb der while-Schleife erzeugen, die dann auch entsprechende Zeilen-Werte für alle Artikel ausgibt. |
| GM=$(while read A B C D E F G H; do GM=$(echo "$C+$D+$F+$G+$H" | bC); echo "$GM"; done <<< $(sed '1d' < sa.txt)) |
| echo "$GM" |
|
2753 854 229 729 1989 557 Genauso mit dem BAR-Verkauf |
| GS=$(while read A B C D E F G H; do GS=$(echo "($C+$D)*$B+($F+$G+$H)*$E" | bC); echo "$GS"; done <<< $(sed '1d' < sa.txt)) |
| echo "$GS" |
|
99.64 47.53 19.67 84.28 294.45 109.80 Nun kann man Spaltenbeschriftungen einfügen und die neuen Spalten und die alte Tabelle aneinanderkleben. Vielleicht noch ein wenig Kosmetik |
| paste <(cat sa.txt) <(sed '1iMenge' <<< "$GM") <(sed '1iVerkauf' <<< "$GS") | column -t |

|
Es könnte natürlich vorkommen daß in einer Woche bei einem
Artikel keine Stückzahl verkauft wurde, die Tabellenzelle wäre
dann leer. In einem solchen Fall ergibt der Aufruf cat sa.txt im Terminal an der Position der LEERZELLE zwei Tabulatorzeichen hintereinander und die Variablenzuordnung gerät durcheinander. Eine Lösung wäre es Tabulatorzeichen Tabulatorzeichen zu ersetzten durch Tabulatorzeichen 0 Tabulatorzeichen Also sed 's/\t\t/\t0\t/g' Nun könnten aber auch mehrere LEERZELLEN hintereinander in einer Zeile vorkommen. Daher muß man das Vorgehen erweitern. Möglich wäre folgendes: $(sed '1d' < sa.txt) zu ersetzen durch $(sed '1d' < sa.txt | sed '/^\t/s/^/0/' | sed '/\t$/s/$/0/' | sed 's/\t\t/\t0\t/g' | sed 's/\t\t/\t0\t/g') Würde nun bei einem Artikel überhaupt keine Stückzahl verkauft, so wäre der Wert von $GSS NULL. Um bei der Prozentberechnung das Teilen durch 0 zu vermeiden, kann man PR=$(echo "($GS+0,00001)*10000/($GSS+0,00001)-10000" | bC | sed 's/\([0-9][0-9]\)$/,\1/') verwenden. |
|
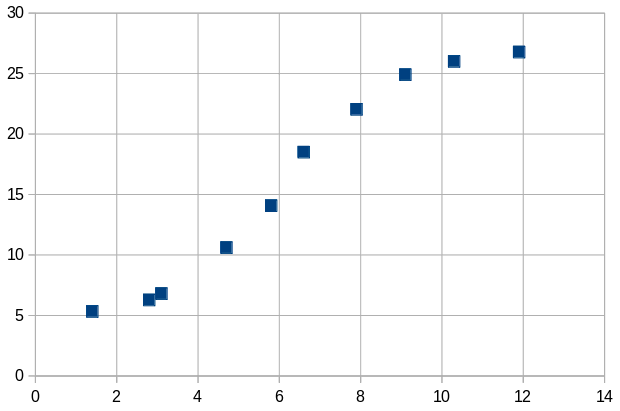
Ein anderes Beispiel: Man hat eine Reihe von Meßwerten in der Form (x;y) die durch Leerzeichen oder Tabulatorzeichen getrennt in einer Datei hD.txt im Ordner ~/Bla stehen. Aufruf gedit ~/Bla/hD.txt ergibt in diesem Beispiel 1,4 5,33 2,8 6,279 3,1 6,806 4,7 10,612 5,8 14,08 6,6 18,5 7,9 22,04 9,1 24,91 10,3 26,004 11,9 26,776 Wichtig ist daß der blinkende Cursor in der Datei ganz unten hinter der letzten Zahl steht und nicht in einer neuen Zeile unter den Zahlen. Sonst drückt man die Rückwärtstaste damit der blinkende Cursor hinter dem letzten Zahlenwert erscheint und speichert. Ansonsten hat man eine zusätzliche LEERZEILE, die man entfernen müßte. Man kann sich diese Meßwerte als Funktion y=y(x) vorstellen |
|
Es läßt sich eine Kurve erahnen von der man die Tangentensteigung
bestimmen möchte - also bei den vorgegebenen x-Meßwerten y'(x).
Näherungsweise läßt sich dies durch einen Differenzenquotienten
berechnen y'(x)~[y(nachx) - y(vorx)]/[nachx - vorx] Dabei ist nachx der in der Reihenfolge nach x notierte Wert und vorx der in der Reihenfolge vor x notierte Wert. Zum Bearbeiten ist es sinnvoll eine Datei zu haben bei der in einer Zeile die Daten vorher aktuell nachher notiert sind, so wie in dem gelb markierten Bereich: |
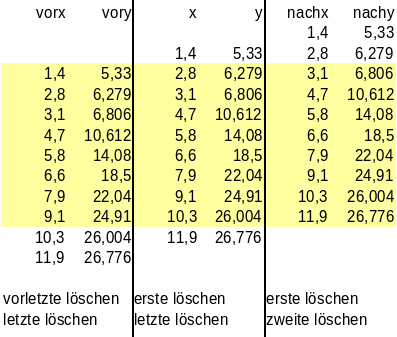
| Also die vorhandene Datei dreimal versetzt aneinanderkleben wobei die entsprechenden Zeilen gelöscht werden. Dies macht die folgende Variable |
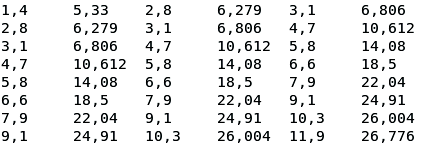
| hDz=$(paste <(sed '$d' < hD.txt | sed '$d') <(sed '1d;$d' < hD.txt) <(sed '1,2d' < hD.txt)) |
| echo "$hDz" |
|
Man wünscht eine Tabelle der Form x y(x) y'(x) natürlich mit einem angenäherten y'(x) Dies erreicht man durch (zum Schluß vielleicht noch ein wenig Kosmetik) |
| VNx=$(while read vorx vory x y nachx nachy; do GS=$(echo "($nachy - $vory)/($nachx - $vorx)" | bC -l); echo "$x $y $GS"; done <<<$hDz) |
| echo "$VNx" | column -t |

|
Noch eine Anmerkung zu der Erzeugung der obigen 30 Variablen mit read. Da
read nur die erste Zeile liest kann man head -n 1 weglassen und diese 30 Variablen erzeugen durch for i in {01..30}; do read zS$i <<< $(cat ~/.meine_sonderzeichen/zS$i.txt | cut -c 1-10); done Man kann also keine mehrzeiligen Variablen auf diese Art mit read
erzeugen. Aber es gibt eine andere Möglichkeit auch mehrzeilige Variablen
zu erzeugen. So kann man die erste Variable auf dieser Seite |
| printf -v dN "$(cat hK.txt)" |
| echo "$dN" |
|
1:28:2:3:0:1 2:8:3:1:1:0 2:31:8:11:3:0 2:18:4:3:4:0 Auf der Seite Debian Gnome Programmfenster Zwischenablage wurden 8 (mehrzeilige) Variablen definiert: zA1=$(cat
~/.meine_zwischenablage/zA1.txt | cut -c 1-60 | head -n 3) |
| for i in {1..8}; do printf -v zA$i "$(cat ~/.meine_zwischenablage/zA$i.txt | cut -c 1-60 | head -n 3)"; done |